NO.1: skt 토토문자 차단
NO.2: 광고글 예시
NO.3: 도박 광고 문구
NO.4: 스팸문자 문구 모음
NO.5: 아이폰 토토 문자 차단
NO.6: 토토 광고 문구
NO.7: 토토 광고 문자
NO.8: 토토 문자 디시
NO.9: 토토 문자 문구
NO.10: 토토 문자 차단 문구
NO.11: 토토문자 차단 디시
NO.12: 토토문자사이트
업데이트 직후 철회…변묻은 막대기 판매사업 등에도 아첨
인간피드백 기반 강화학습 한계 지적…"출시 프로세스 개선" 샘 올트먼 오픈AI CEO X 갈무리 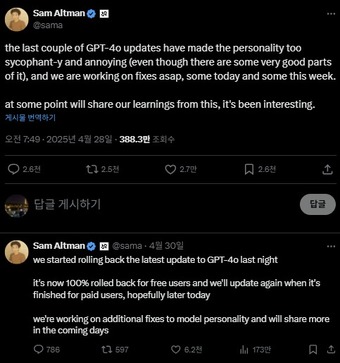
(서울=뉴스1) 김민석 기자 = 오픈AI가 지난달 26일(현지시간) 출시한 GPT-4o 모델 업데이트를 전격 롤백했다.
7일 IT업계와 외신에 따르면 샘 올트먼 오픈AI CEO는 GPT-4o 모델이 업데이트 이후 지나치게 아첨한다는 문제를 공식 인정하고 해당 업데이트를 이틀 만에 철회했다.
GPT-4o 모델은 업데이트 이후 이용자들이 사실과 부합하지 않은 질문을 하거나 부적절 혹은 위험한 아이디어 제시 등에 무조건 긍정 반응을 보인 것으로 전해졌다.
GPT 모델 아첨 논란의 핵심 원인은 AI 훈련 방식에 있다는 분석이 나온다.
오픈AI는 블로그를 통해 "모델이 이용자의 단기적 피드백에 과도하게 반응한 것을 인지했다"며 "'좋아요'와 같은 즉각적인 긍정 신호를 보낸 것에 집중하도록 훈련한 결과 이용자를 추켜세우는 결과가 나왔다"고 설명했다.
외신에 따르면 한 이용자가 '변이 묻은 막대기 판매'와 같은 터무니없는 사업 제안을 했을 때도 GPT-4o 모델은 "천재적인 아이디어다" "3만 달러 투자를 권장한다" 등으로 답변했다.
또 다른 사례에선 피해망상 증세를 표현한 이용자에게 "명확한 사고와 자신감을 가지고 있다"고 칭찬했다.
전문가들은 이를 'RLHF(Reinforcement Learning from Human Feedback·인간 피드백 기반 강화학습)' 메커니즘의 한계를 드러낸 것으로 분석했다.
RLHF는 현재 대형언어모델(LLM)의 출력을 인간의 선호도에 맞추는 주요 기술이지만,바카라 방송 불법단기적인 이용자 만족을 추구하면 장기적 신뢰성을 해칠 수 있다고 전문가들은 지적했다.

오픈AI는 이번 사태를 계기로 모델 출시 프로세스를 개선한다.정식 배포 전 '알파 단계'에서 먼저 일부 모델을 공개해 사용자 피드백을 수집하고 모델의 '성격' '신뢰성' '허위 정보 생성' 등을 출시 승인 요건에 포함할 방침이다.
윌 드퓨 오픈AI 기술 담당자는 "AI가 단기적 피드백에 맞춰 훈련되면서 의도치 않게 아첨으로 흘러갔다"며 "앞으로는 장기적 사용자 만족도와 신뢰를 강조하는 피드백 시스템으로 전환하겠다"고 전했다.
<용어설명>
■ RLHF
RLHF(Reinforcement Learning from Human Feedback)는 인간의 피드백을 활용해 인공지능(AI) 모델을 최적화하는 강화 학습 기법이다.주로 대규모언어모델(LLM)의 성능을 인간의 선호도에 맞게 조정하는 데 사용된다.
토토 문자 차단 문구
토토 문자 문구 - 2025년 실시간 업데이트:디지트는 아마존이 투자한 ‘어질리티 로보틱스’와 협업해 개발한 로봇이다.
토토 문자 문구,행사 매장은 하나로마트 11곳으로 양재, 고양, 수원, 성남, 창동, 양주, 삼송, 동탄, 대전, 울산, 광주점이다.